WRF
WRF est un modèle climatique régional, utilisé à la fois en recherche et en prévision opérationnelle du temps, et développé principalement au National Center for Atmospheric Research (NCAR, Etats-Unis). Cette page présente les méthodes de compilation et d’utilisation de WRF version 3 sur le cluster de calcul de l’université de Bourgogne.
Le modèle climatique WRF: présentation rapide, compilation, utilisation
NOTE. Les instructions données ci-après s’appliquent à la version 3 du modèle WRF (coeur ARW : Advanced Research WRF), compilé avec le compilateur Fortran Intel. Les informations contenues dans cette page sont fournies sans aucune garantie : elles nécessitent d’être adaptées aux ressources informatiques des utilisateurs.
Mise à jour : février 2015 pour WRF-ARW v3.6.1
Partie 1. Présentation du modèle
Le modèle WRF est un modèle climatique à aire géographique limitée. Le modèle résout explicitement les équations de la dynamique qui assure la conservation et implémente les principaux processus physiques en lien avec le climat (Skamarock et al. (2008)) à savoir :
– échanges et transferts radiatif aux courtes et grandes longueurs d’onde ;
– mouvements et turbulence dans la couche limite planétaire ;
– schémas de convection et microphysique des nuages ;
– interaction eau, sol, végétation et pôle urbain avec les basses couches de l’atmosphère.
Ces éléments constituent le coeur de l’application. A cela s’ajoute un module de preprocessing.
1.1 Noyau dynamique et composantes physiques
La résolution des équations de la dynamique à haute résolution s’appuie sur la formulation non-hydrostatique des équations de la mécanique des fluides et de la thermodynamique. WRF implémente le formalisme eulérien de ces équations et propose deux noyaux qui diffèrent principalement dans leur mode d’utilisation du modèle.
– Le noyau Non-Hydrostatique Meso-scale Model (NMM) est utilisé pour la prévision météorologique opérationnelle. Ce noyau est développé par le NOAA/NCEP (National Oceanic and Atmospheric Administration/ National Centers for Environmental Prediction) ;
– Le noyau Advanced Research WRF (ARW)) développé par le NCAR (National Center for Atmospheric Research) correspond à l’état de l’art de la résolution dynamique des schémas physiques les plus récents.
La version WRF/ARW est une plate-forme de recherche sur la simulation numérique régionale du climat. Conformément à ce qui est présenté à la Figure 1.1, elle offre une large gamme de configurations de simulation, allant de cas idéalisés en 2D et 3D au mode “real” alimenté par les données simulées larges échelles (ré-analyses, GCM) et / ou par assimilation de données provenant de réseaux d’observation terrestres et satellitaux. Des modules dédiés à la pollution atmosphérique et aux problèmes environnementaux (i.e. incendies) sont également disponibles.
L’utilisation du modèle se fera ici en mode “real” qui est la configuration généralement utilisée pour la désagrégation dynamique climatique.

1.2 Désagrégation : la technique de nesting
Une spécificité importante des RCM est la simulation du climat sur un espace géographique limité de la surface de la Terre. L’idée ici est de se concentrer sur la simulation du climat à des résolutions difficilement abordables par les modèles globaux, par l’intermédiaire d’un raffinement horizontal. En théorie le formalisme du modèle régional permet un raffinement « illimité », jusqu’aux échelles fines topo- et micro-climatiques. Dans la pratique cette possibilité se heurte toutefois à la contrainte des ressources informatiques (temps de calcul et stockage) et au réalisme des « conditions aux limites » (états de surface : relief, occupation du sol, etc).
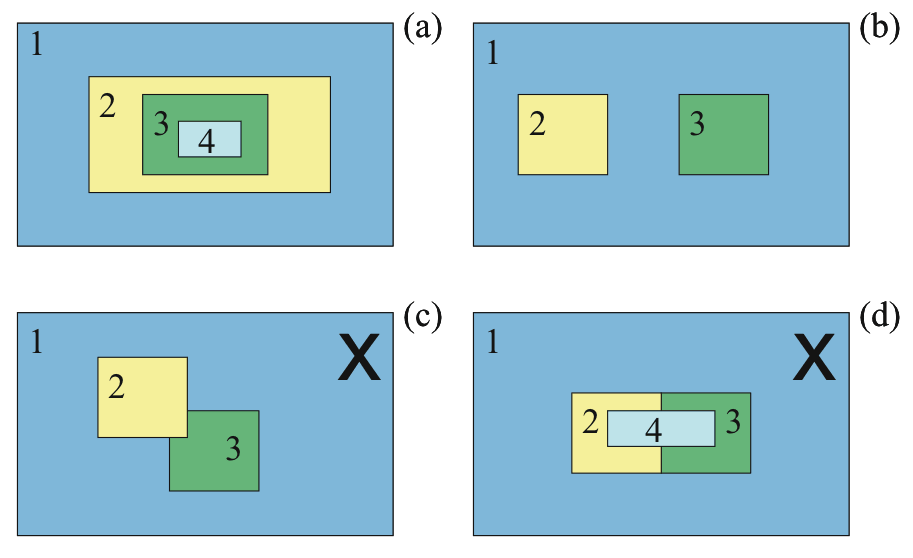
La descente d’échelle ou désagrégation se fait par emboîtements successifs de domaines dont la résolution (c’est-à-dire la taille de la maille) est améliorée entre chaque domaine d’un facteur 2 à 5. La Figure 1.2 présente les configurations d’emboîtement autorisées et non autorisées par le modèle.
Cette descente d’échelle s’accompagne d’échanges entre les domaines selon deux modes : « one-way » ou « two-way » nesting.
– 1-way nesting : les informations échangées ne se font que du domaine à maille large vers le domaine à plus fine maille. Ainsi les conditions aux limites des domaines emboîtés sont données par le domaine parent, excepté pour le domaine 1 qui est forcé par un modèle global.
– 2-way nesting : ce mode inclut en plus des conditions aux limites une communication des domaines à fine maille, les domaines imbriqués pouvant influencer leurs domaines parents en retour.
1.3 Code informatique et parallélisation
Le modèle est codé en langage fortran90/95 et C massivement parallélisé. La parallélisation consiste à répartir la charge de calcul sur plusieurs processeurs. Les multiples tâches de calcul nécessitent des communications entre elles pour leur synchronisation et l’échange d’information. Cela se fait à partir du protocole implémenté dans la librairie MPI (Message Parsing Interface) lorsqu’on utilise de la mémoire distribuée (distributed memory) et/ou avec la librairie OPENMPI lorsqu’on utilise de la mémoire partagée (shared memory).
Même si la parallélisation massive permet de réduire le coût en calcul, l’utilisation du modèle n’est réaliste que dans un environnement de calcul scientifique intensif, i.e. au sein de supercalculateurs ou de grappes / fermes (cluster) de calcul. Son utilisation nécessite également des ressources mémoire très importantes et de disposer d’un espace de stockage conséquent.
Partie 2. Compilation du modèle WRF
La compilation se déroule en 2 étapes :
1. la compilation du noyau ARW ;
2. la compilation du système de pré-traitement WRF Preprocessing System (WPS).
Ces deux éléments partagent les routines d’entrées et de sorties WRF I/O API. La compilation se fait sur les machines du cluster du Centre de Calcul de l’Université de Bourgogne (CCUB).
Les librairies nécessaires à la compilation sont :
– Compilateur FORTRAN 90/95 : ici Intel ;
– Compilateur C : ici gcc;
– Perl ;
– NetCDF ;
– MPI ;
2.1 La compilation du noyau ARW
Récupération du code source dans votre répertoire de travail et décompression des fichiers archives :
tar -xf WPSV3.6.1.TAR.gz
tar -xf WRFV3.6.1.TAR.gz
Vous disposez maintenant de deux nouveaux dossiers WRFV3 et WPS. Pour procéder à la compilation afin d’obtenir les exécutables du modèle, il faut :
1. définir les options de compilation en fonction du type de machine, du compilateur et des librairies ;
2. définir l’environnement de compilation parallèle ;
3. lancer la compilation.
cd WRFV3
ls -l
Vous trouvez dans le dossier le contenu suivant :
Registry/ Dossier pour les fichiers Registry
arch/ Dossier de collecte des options de compilation
clean script pour nettoyer les fichiers créés et les exécutables
compile script pour la compilation du code
configure script de génération du fichier configure.wrf
chem/ WRF chimie de la NOAA/GSD
dyn_em/ Dossier du noyau ARW
dyn_exp/ Dossier noyau expérimental
dyn_nmm/ Dossier du noyau NMM
external/ Dossier des paquetages externes pour ES, temps et MPI
frame/ Dossier de WRF framework
inc/ Dossier des fichiers d’entête (include)
main/ Dossier des routines du type wrf.F et des exécutables
phys/ Dossier des modules physiques
run/ Dossier pour l’exécution de WRF
share/ Dossier des modules de médiation et d’ES
test/ Dossier de tests
tools/ Dossier outils de développement
La compilation se réalise avec les commandes suivantes ; elle nécessite des patchs permettant d’optimiser le calcul de certaines routines utilisant des filtres basés sur des transformées de Fourie (dans le code, il s’agit des filtres polaires, activés pour les hautes latitudes).
Le fichier configure.wrf peut être obtenu ICI. Il doit être copié dans le répertoire de travail (WRFV3). Dans l’exemple présent, WRF est compilé en parallèle à l’aide du compilateur fortran Intel.
module load openmpi/intel/13.1.3
module load netcdf/4.3.0/intel/13.1.3
module load jasper/1.900.1/intel/13.1.3
module load hdf5/1.8.11/intel/13.1.3
export WRFIO_NCD_LARGE_FILE_SUPPORT=1
export NETCDF=$NETCDFROOT
export NETCDF4=1
export JASPERINC=$JASPERROOT/include/jasper
export JASPERLIB=$JASPERROOT/lib
export HDF5_PATH=$HDF5ROOT
export CURL_PATH=/usr/lib64
export WRF_EM_CORE=1
tar xvf ../WRFV3.5-CCUBPATCH.tar
./configure
19. Linux x86_64 i486 i586 i686, ifort compiler with icc (dmpar)
Compile for nesting? (1=basic, 2=preset moves, 3=vortex following) [default 1]: 1
cp ../configure.wrf-ompi-intel13.1.1-MKL-FULLOPTIM configure.wrf
patch -p1 < ../0001-mkl-fft-for-polar-filters.patch
./compile -j 20 em_real 2>&1 | tee COMPILE.log
Une fois l’opération terminée, on vérifie que les fichiers exécutables notamment wrf.exe et real.exe sont bien générés.
ls -l main/*.exe
On peut ensuite passer à la deuxième étape, la compilation du WRF Preprocessing System (WPS).
2.2 La compilation de WPS
Note : La compilation de WPS doit obligatoirement être réalisée après celle du noyau ARW.
cd ../WPS
module load netcdf/4.3.0/intel/13.1.3
module load intel/13.1.3
module load jasper/1.900.1/intel/13.1.3
module load hdf5/1.8.11/intel/13.1.3
export NETCDF=$NETCDFROOT
export JASPERINC=$JASPERROOT/include/jasper
export JASPERLIB=$JASPERROOT/lib
./configure
17. Linux x86_64, Intel compiler (serial)
Enter selection [1-26] : 13
cp ../configure.wps-seq-intel13.1.1 configure.wps
./compile 2>&1 | tee COMPILE.log
Le fichier configure.wps peut être obtenu ICI. Il doit être copié dans le répertoire de travail (WPS). Dans l’exemple présent, WPS est compilé en mode séquentiel (code non parallélisé).
Si la compilation est réussie vous devez avoir 3 nouveaux exécutables : geogrid.exe, ungrib.exe et metgrid.exe.
– geogrid.exe : définit la taille/localisation des domaines et extrait les données d’entrée statiques ;
– ungrib.exe : extrait les champs météorologiques des fichiers GRIB ;
– ungrib.exe : réalise l’interpolation horizontale des champs météorologiques (issus de ungrib) à la maille de simulation des domaines (définis par geogrid).
Nous pouvons maintenant passer à la phase de définition du domaine et de pre-processing des données.
Partie 3. Préparation des données avec WPS
La préparation des données passe par la configuration du fichier namelist.wps. Ce fichier est la clé de voute pour la préparation des données. C’est dans ce fichier que 1) la période et l’aire géographique sont définies 2) les données d’entrée statiques et dynamiques utilisées sont sélectionnées, 3) l’interpolation des données à la maille de simulation est effectuée et 4) le format des données est fixé.
3.1 Définition des domaines simulation
Il existe deux manières de créer des domaines emboîtés :
– manuellement en ajustant les valeurs de la partie &geogrid du fichier namelist.input ;
– interactivement en utilisant l’interface WRF Domain Wizard.
3.1.1 La localisation et taille des domaines
C’est le premier domaine qui fixe la fenêtre géographique de l’aire de simulation par l’intermédiaire des coordonnées géographiques du centre. Les domaines emboîtés ne sont localisés que par rapport au domaine parent (domaine 1 pour le domaine 2, domaine 2 pour le domaine 3 etc.). La Figure 3.1 présente le mode de localisation utilisé par WPS.
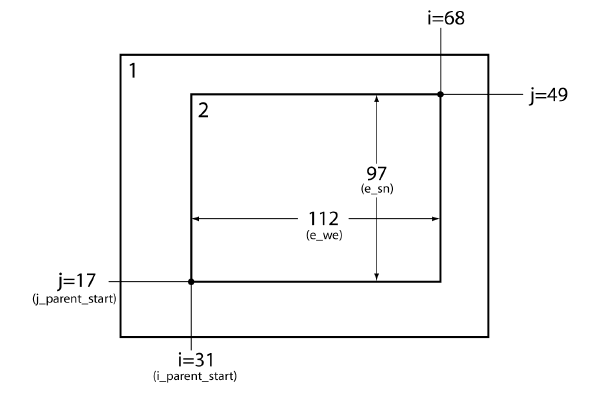
Le domaine 1 est centré sur 45N et 4.7E. Les domaines sont par exemple définis dans le namelist.input comme suit :
&geogrid
parent_id = 1,1,
parent_grid_ratio = 1,3,
i_parent_start = 1,31
j_parent_start = 1,17
e_we = 74,112
e_sn = 61,97
geog_data_res = ’10m’,’5m’
dx = 30000,
dy = 30000,
map_proj = ‘lambert’,
ref_lat = 45.0,
ref_lon = 4.7,
truelat1 = 42.0,
truelat2 = 47.0,
stand_lon = 4.7,
geog_data_path = ‘/work/crct/shared/geogv35’
Si ces réglages peuvent sembler peu intuitifs, il est possible d’utiliser l’application WRF Domain Wizard, qui permet de définir les domaines de manière interactive avec interface graphique.
3.1.2 WRF Domain Wizard
Lancer l’application :
wrfdw &
Lors du premier lancement il faut renseigner les chemins d’accès et créer le répertoire qui accueillera les paramètres de localisation. Une fois les domaines définis, les paramètres de localisation générés via wrfdw sont à copier dans la namelist.wps.
3.2 Les trois étapes du preprocessing
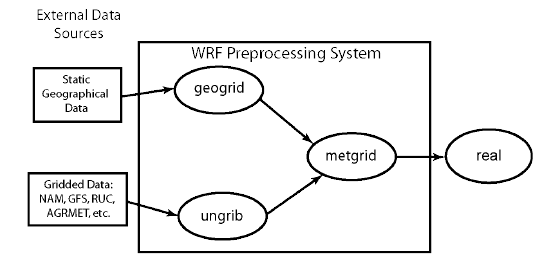
Les principales étapes du preprocessing sont résumées par la Figure 3.2.
3.2.1 Geogrid
Interpolation des champs terrestres statiques à la maille de simulation.
Etape 1 : Edition de namelist.wps
Pour geogrid seuls les éléments &share et &geogrid de namelist.wps nécessitent d’être édités.
– la partie &share permet d’indiquer quel noyau est utilisé (ici ARW), le nombre total de domaines, le format de sortie des données (2=NetCDF) ;
– la partie &geogrid fixe le domaine géographique à simuler, le type de projection géographique et les chemins d’accès aux données de surface.
Les données de surface sont issues de l’USGS (United State Geological Survey), du satellite MODIS, ou d’autres bases de données (exemple : CORINE Land Cover sur l’Europe, modèle numérique de terrain de l’IGN pour la France, etc.). Ces bases contiennent les données de sol, de végétation, de relief, d’albédo. Ces données sont fournies pour 4 résolutions spatiales : 10m-arc, 5m-arc, 2m-arc et 30sec-arc.
&share
wrf_core = ‘ARW’,
max_dom = 2,
start_date = ‘1989-01-01_00:00:00′,’1989-01-01_00:00:00’
end_date = ‘1992-12-31_18:00:00′,’1992-12-31_18:00:00’
interval_seconds = 21600,
io_form_geogrid = 2,
/
&geogrid
parent_id = 1,1,
parent_grid_ratio = 1,4,
i_parent_start = 1,29,
j_parent_start = 1,12,
e_we = 80,93,
e_sn = 34,49,
geog_data_res = ’10m’,’2m’,
dx = 1.181168,
dy = 1.125966,
map_proj = ‘lat-lon’,
ref_lat = 45.56,
ref_lon = 4.693,
truelat1 = 45.56,
truelat2 = 45.56,
stand_lon = 4.693,
geog_data_path = ‘/work/crct/shared/geog’
opt_geogrid_tbl_path = ‘geogrid/’
/
Etape 2 : Vérifier que GEOGRID.TBL est lié à la bonne version de table
Il y a plusieurs GEOGRID.TBL en fonction des noyaux dynamiques :
– GEOGRID.TBL.ARW pour ARW ;
– GEOGRID.TBL.NMM pour NMM.
ls -l geogrid/GEOGRID.TBL
GEOGRID.TBL -> GEOGRID.TBL.ARW
Etape 3 : Lancer geogrid.exe
./geogrid.exe
Parsed 11 entries in GEOGRID.TBL
Processing domain 1 of 3
Processing XLAT and XLONG
Processing MAPFAC
Processing F and E
Processing ROTANG
Processing LANDUSEF
Calculating landmask from LANDUSEF ( WATER = 16 )
Processing HGT_M
Processing HGT_U
Processing HGT_V
Processing SOILTEMP
Processing SOILCTOP
Processing SOILCBOT
Processing ALBEDO12M
Processing GREENFRAC
Processing SNOALB
Processing SLOPECAT
Processing SLOPECAT
Processing domain 2 of 3
Processing XLAT and XLONG
Processing MAPFAC
Processing F and E
……
!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
! Successful completion of geogrid. !
!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
Si une erreur survient lors de l’exécution il faut analyser les messages contenus dans le fichier geogrid.log.
Si l’exécution s’est bien déroulée vous devez avoir dans votre répertoire autant de fichiers avec le préfixe geo_em.d0<numéro de domaine>.nc que de domaine.
ls -l geo_em*
geo_em.d01.nc
geo_em.d02.nc
geo_em.d03.nc
3.2.2 Ungrib
Etape 1 : Edition des parties &share et &ungrib de namelist.wps
La partie &share permet d’indiquer la période d’extraction des données et le pas de temps des données (21600=6hrs).
La partie &ungrib indique dans quel format binaire intermédiaire seront les données (WPS, SI, MM5). Le format WPS est recommandé.
Enfin il convient de préciser le répertoire et le préfixe du nom des fichiers intermédiaires qui sont produits.
&share
wrf_core = ‘ARW’,
max_dom = 2,
start_date = ‘1989-01-01_00:00:00′,’1989-01-01_00:00:00’
end_date = ‘1992-12-31_18:00:00′,’1992-12-31_18:00:00’
interval_seconds = 21600,
io_form_geogrid = 2,
/
&ungrib
out_format = ‘WPS’,
prefix = ‘FILE’,
/
Etape 2 : Faire un lien sur les fichiers GRIB
Les fichiers GRIB sont les fichiers qui contiennent les variables météorologiques, de surface terrestre et des océans de large échelle qui sont utilisées pour fixer les conditions aux bornes.
link_grib.csh /work/crct/shared/ERA_INTERIM/era_int_1990*
ls -l GRIBFILE.*
GRIBFILE.AAA -> /work/crct/shared/ERA_INTERIM/era_int_1990s1_prs.grb
GRIBFILE.AAB -> /work/crct/shared/ERA_INTERIM/era_int_1990s2_prs.grb
GRIBFILE.AAC -> /work/crct/shared/ERA_INTERIM/era_int_1990_sfc.grb
Etape 3 : Utiliser le bon fichier Vtable et exécuter ungrib.exe
Le fichier Vtable est nécessaire à ungrib car il permet d’identifier les variables météorologiques, de surface terrestre et des océans à extraires du fichier GRIB.
Note 1 : Il convient de traiter séparément les données SST des autres données. Ceci nécessite donc de manipuler deux fichiers Vtable : Vtable_prs_anaecm (disponible ICI) et Vtable_sst_anaecm (disponible ICI).
Note 2 : Pensez à modifier le préfixe pour les noms des fichiers intermédiaires. Ici on utilisera 2 préfixes pour les SST d’une part et pour l’ensemble des autres variables d’autre part.
cp Vtable_prs_anaecm Vtable
./ungrib.exe
PRES GEOPT HGT TT UU VV RH DEWPT LANDSEA …
———————————————————
1000.0 X X X X X
_925.0 X X X X X
….
Pensez à éditer namelist.wps pour changer le préfixe des fichiers intermédiaires.
cp Vtable_sst_anaecm Vtable
./ungrib.exe
Inventory for date = 1990-01-08 00:00:00
PRES SST
———————————————————–
2001.0 X
———————————————————–
….
Si l’exécution se termine par une erreur il faut analyser les messages qui sont contenus dans le fichier ungrib.log.
Si l’exécution est un succès, les fichiers intermédiaires préfixés ont été générés et sont utilisés pour la dernière étape du preprocessing.
3.2.3 Metgrid
Etape 1 : Edition des parties &share et &metgrid de namelist.wps
Ici on s’assurera que tous les préfixes des fichiers intermédiaires sont présents.
&share
wrf_core = ‘ARW’,
max_dom = 2,
start_date = ‘1989-01-01_00:00:00′,’1989-01-01_00:00:00’
end_date = ‘1992-12-31_18:00:00′,’1992-12-31_18:00:00’
interval_seconds = 21600,
io_form_geogrid = 2,
/
&metgrid
fg_name = ‘FILE’ ‘SST_FILE’
io_form_metgrid = 2,
opt_metgrid_tbl_path = ‘metgrid/’,
/
Etape 2 : Vérifier que METGRIB.TBL est lié à la bonne version
Le fichier METGRIB.TBL précise le type d’interpolation en fonction du champ. Il y a plusieurs METGRID.TBL en fonction des noyaux dynamiques :
– METGRID.TBL.ARW pour ARW ;
– METGRID.TBL.NMM pour NMM ;
ls -l metgrid/METGRID.TBL
METGRID.TBL -> METGRID.TBL.ARW
Etape 3 : Lancer metgrid.exe
./metgrid.exe
Si le calcul se termine par une erreur il faut analyser les messages contenus dans le fichier metgrid.log
Si le calcul s’est bien déroulée, les fichiers préfixés met_em ont été créés pour chaque pas de temps et pour tous les domaines. L’étape de préparation des données est terminée. Les fichiers met_em vont maintenant servir pour l’étape de création des “inputs” nécessaires pour l’initialisation et la simulation.
Pour gagner de l’espace disque il est possible (mais bien sûr pas obligatoire), à ce stade, de supprimer les fichiers temporaires générés par WPS :
rm FILE* SST_FILE*
Il peut être pertinent de les conserver pour économiser l’étape ungrib.exe dans l’hypothèse où ces fichiers pourraient être rapidement réutilisés (en ce cas les migrer sous le serveur d’archivage /archive peut être envisageable pour ne pas encombrer inutilement le serveur de travail haute perfoemance /work).
Partie 4. Initialisation et simulation
Les étapes clés de la simulation sont précédées par l’initialisation à partir des fichiers met_em. Ces deux étapes passent également par la configuration du fichier namelist.input. Ce fichier est le noeud du système. Il permet de préciser le pas de temps entre chaque calcul, les schémas physiques retenus, les options de la résolution des équations, le format de sortie, le guidage, etc.
4.1 Le fichier de paramétrisation namelist.input
Voir Wang et al. (2009) pour une description détaillée du fichier, ou le fichier README.namelist qui se trouve dans le répertoire WRFV3/run. Les principaux items du fichiers sont :
– time_control qui fixe la période, le pas des inputs et des fichiers de reprises, le format numérique des simulations ;
– domains similaire à ce qui est contenu dans namelist.wps, fixe le pas de temps pour la résolution ;
– physics permet de paramétrer les 7 principaux processus physiques implémentés :
1. microphysique des nuages mp_physics
2. radiation grande longueur d’onde ra_lw_physics
3. radiation courte longueur d’onde ra_sw_physics
4. schéma de flux de surface (coefficients de friction et d’échange) sf_sfclay_physics
5. schéma d’interaction de surface (Land Surface Model) sf_surface_physics
6. couche limite planétaire bl_pbl_physics
7. physique des cumulus cu_physics
– fdda permet de guider le modèle (« nudging » spectral ou en points de grille);
– dynamics options de diffusion, d’advection ;
– bdy_control contrôle la prescription des conditions aux limites atmosphériques.
Potentiellement l’ensemble des options physiques de base offrent plus de 600 000 combinaisons différentes. Le choix des options est une étape délicate de la simulation numérique climatique. Il n’existe pas de combinaison universelle.
4.2 Création des fichiers d’initialisation avec real.exe
Les fichiers d’initialisation et de rappel du modèle sont constitués à partir des fichiers met_em et des items time_control, domain du fichier namelist.input et de l’exécutable real.exe.
Note 1 : real.exe et wrf.exe doivent être éxécutés en mode batch. Pour cela on utilisera les scripts batch realjob (exemple ICI) et wrfjob (exemple ICI), placés dans le répertoire WRFV3/run.
Note 2 : il faut éditer ces scripts batch pour jouer sur le nombre de processeurs utilisés pour le calcul. C’est le système de gestion de batch SGE (Sun Grid Engine) qui se charge ensuite de la répartition en fonction de la charge du cluster.
Note 3 : il existe une option permettant d’archiver des sorties additionnelles à des pas de temps plus fins (par exemple, températures ou pluies horaires). Les détails de la syntaxe sont indiqués dans le README.namelist mais cette option requierts des fichiers texte, à placer dans le répertoire WRFV3/run, listant les paramètres à archiver et la fréquence souhaitée d’archivage. Il en faut un par domaine de simulation : l’exemple fourni ICI permet de sauvegarder les pluies convectives (RAINC), non convectives (RAINNC), la température à 2 mètres (T2) et le vent à 10 mètres (U10, V10).
cd WRFV3/run
ln -s ../../WPS/<votre répertoire met file>/met_em* .
module load openmpi/intel/13.1.3
module load netcdf/4.3.0/intel/13.1.3
module load intel/13.1.3
module load jasper/1.900.1/intel/13.1.3
module load hdf5/1.8.11/intel/13.1.3
qsub realjob
Un fois le process terminé vous devez avoir dans votre répertoire le fichier wrfbdy_d01 et autant de fichiers que de domaines wrfinput_d0<numéro du domaine>. Si les options de guidage sont activées (grid_fdda = 1 ou 2 dans la section &fdda de namelist.input), des fichiers wrffdda_d0<numéro du domaine> sont également créés. A ce stade la simulation climatique peut être lancée.
4.3 Simulation avec wrf.exe
Editer wrfjob pour choisir le nombre de processeurs sur lequel s’exécutera le calcul. Il ne reste ensuite qu’à soumettre le job et attendre.
rm rsl.*
module load openmpi/intel/13.1.3
module load netcdf/4.3.0/intel/13.1.3
module load intel/13.1.3
module load jasper/1.900.1/intel/13.1.3
module load hdf5/1.8.10-patch1/intel/13.1.3
qsub wrfjob
Les résultats sont contenus dans les fichiers wrfout_d<numéro du domaine>_<date de départ> au format NetCDF (.nc). Une fois ces fichiers créés et le job terminé, les fichiers temporaires peuvent être détruits.
rm met_em* wrfrst* wrfbdy* wrfinput* rsl.* *.o* *.po*
Choix du nombre de processeurs
En pratique le cluster de l’université de Bourgogne autorise des jobs à tourner sur un maximum de 64 processeurs. Toutefois, le code lui-même peut parfois apporter des restrictions supplémentaires. La formule empirique ci-dessous permet de calculer le nombre maximal de processeurs à ne pas dépasser, en fonction de la taille du domaine simulé (nombre de points de grille en latitude et longitude) :
– soient M et N le nombre de points de grille en latitude et longitude, respectivement
– pour le premier domaine WRF, on calcule E(M/6) et E(N/6) où E est la fonction mathématique partie entière
– NPROC = E(M/6) * E(N/6)
– si l’expérience utilise des domaines emboîtés (nesting, cf. partie 1.1.2), les mêmes opérations sont répétées pour les domaines nestés, en remplaçant le facteur 6 par 9.
– le nombre de processeurs maximal à retenir correspond à la plus petite des valeurs ainsi trouvées, pour les k domaines simulés.
Note 1 : l’architecture des machines de calcul suggère de choisir un nombre de processeurs qui soit un multiple de 8.
Note 2 : le temps d’attente des jobs est d’autant plus long que le nombre de processeurs est élevé, il s’agit donc de trouver un bon compromis entre temps d’attente et temps d’exécution en fonction de la charge du cluster.
Note 3 : les gains en temps d’exécution ne sont pas linéaires en fonction du nombre de processeurs.
Bibliographie
W. C. Skamarock, J. B. Klemp, J. Dudhia, D. O. Gill, D. M. Barker, M. G. Duda, X.-Y. Huang, W. Wang, and P. J. G. A description of the Advanced Research WRF Version 3. Technical report, National Center for Atmospheric Reasearch, Boulder – Colorado , USA, 2008. 125p.
W. Wang, C. Bruyère, M. Duda, J. Dudhia, D. Gill, H.-C. Lin, J. Michalakes, S. Rizvi, and X. Zhang. ARW Modeling System User’s Guide version 3.1. NCAR, Boulder – Colorado, USA, April 2009.
- kc_data:
- a:8:{i:0;s:0:"";s:4:"mode";s:0:"";s:3:"css";s:0:"";s:9:"max_width";s:0:"";s:7:"classes";s:0:"";s:9:"thumbnail";s:0:"";s:9:"collapsed";s:0:"";s:9:"optimized";s:0:"";}
- kc_raw_content:
WRF est un modèle climatique régional, utilisé à la fois en recherche et en prévision opérationnelle du temps, et développé principalement au National Center for Atmospheric Research (NCAR, Etats-Unis). Cette page présente les méthodes de compilation et d'utilisation de WRF version 3 sur le cluster de calcul de l'université de Bourgogne.
Le modèle climatique WRF: présentation rapide, compilation, utilisation
Contributeurs : Thierry Castel, Pascal Roucou, Julien Crétat, Benjamin Pohl (CRC), avec l'aide de Didier Rebeix (DSI-CCuB)
NOTE. Les instructions données ci-après s'appliquent à la version 3 du modèle WRF (coeur ARW : Advanced Research WRF), compilé avec le compilateur Fortran Intel. Les informations contenues dans cette page sont fournies sans aucune garantie : elles nécessitent d'être adaptées aux ressources informatiques des utilisateurs.
Mise à jour : février 2015 pour WRF-ARW v3.6.1
Partie 1. Présentation du modèle
Le modèle WRF est un modèle climatique à aire géographique limitée. Le modèle résout explicitement les équations de la dynamique qui assure la conservation et implémente les principaux processus physiques en lien avec le climat (Skamarock et al. (2008)) à savoir :
– échanges et transferts radiatif aux courtes et grandes longueurs d’onde ;
– mouvements et turbulence dans la couche limite planétaire ;
– schémas de convection et microphysique des nuages ;
– interaction eau, sol, végétation et pôle urbain avec les basses couches de l’atmosphère.
Ces éléments constituent le coeur de l’application. A cela s’ajoute un module de preprocessing.
1.1 Noyau dynamique et composantes physiques
La résolution des équations de la dynamique à haute résolution s’appuie sur la formulation non-hydrostatique des équations de la mécanique des fluides et de la thermodynamique. WRF implémente le formalisme eulérien de ces équations et propose deux noyaux qui diffèrent principalement dans leur mode d’utilisation du modèle.
– Le noyau Non-Hydrostatique Meso-scale Model (NMM) est utilisé pour la prévision météorologique opérationnelle. Ce noyau est développé par le NOAA/NCEP (National Oceanic and Atmospheric Administration/ National Centers for Environmental Prediction) ;
– Le noyau Advanced Research WRF (ARW)) développé par le NCAR (National Center for Atmospheric Research) correspond à l’état de l’art de la résolution dynamique des schémas physiques les plus récents.
La version WRF/ARW est une plate-forme de recherche sur la simulation numérique régionale du climat. Conformément à ce qui est présenté à la Figure 1.1, elle offre une large gamme de configurations de simulation, allant de cas idéalisés en 2D et 3D au mode “real” alimenté par les données simulées larges échelles (ré-analyses, GCM) et / ou par assimilation de données provenant de réseaux d’observation terrestres et satellitaux. Des modules dédiés à la pollution atmosphérique et aux problèmes environnementaux (i.e. incendies) sont également disponibles.
L’utilisation du modèle se fera ici en mode “real” qui est la configuration généralement utilisée pour la désagrégation dynamique climatique.Figure 1.1: Organigramme de WRF [d'après Wang et al. 2009]
1.2 Désagrégation : la technique de nesting
Une spécificité importante des RCM est la simulation du climat sur un espace géographique limité de la surface de la Terre. L'idée ici est de se concentrer sur la simulation du climat à des résolutions difficilement abordables par les modèles globaux, par l'intermédiaire d'un raffinement horizontal. En théorie le formalisme du modèle régional permet un raffinement "illimité", jusqu'aux échelles fines topo- et micro-climatiques. Dans la pratique cette possibilité se heurte toutefois à la contrainte des ressources informatiques (temps de calcul et stockage) et au réalisme des "conditions aux limites" (états de surface : relief, occupation du sol, etc).
La descente d'échelle ou désagrégation se fait par emboîtements successifs de domaines dont la résolution (c'est-à-dire la taille de la maille) est améliorée entre chaque domaine d'un facteur 2 à 5. La Figure 1.2 présente les configurations d'emboîtement autorisées et non autorisées par le modèle.Figure 1.2: Configurations de nesting autorisées et non autorisées [d'après Skamarock et al. 2008]
Cette descente d'échelle s'accompagne d'échanges entre les domaines selon deux modes : "one-way" ou "two-way" nesting.
– 1-way nesting : les informations échangées ne se font que du domaine à maille large vers le domaine à plus fine maille. Ainsi les conditions aux limites des domaines emboîtés sont données par le domaine parent, excepté pour le domaine 1 qui est forcé par un modèle global.
– 2-way nesting : ce mode inclut en plus des conditions aux limites une communication des domaines à fine maille, les domaines imbriqués pouvant influencer leurs domaines parents en retour.
1.3 Code informatique et parallélisation
Le modèle est codé en langage fortran90/95 et C massivement parallélisé. La parallélisation consiste à répartir la charge de calcul sur plusieurs processeurs. Les multiples tâches de calcul nécessitent des communications entre elles pour leur synchronisation et l’échange d’information. Cela se fait à partir du protocole implémenté dans la librairie MPI (Message Parsing Interface) lorsqu’on utilise de la mémoire distribuée (distributed memory) et/ou avec la librairie OPENMPI lorsqu’on utilise de la mémoire partagée (shared memory).
Même si la parallélisation massive permet de réduire le coût en calcul, l’utilisation du modèle n’est réaliste que dans un environnement de calcul scientifique intensif, i.e. au sein de supercalculateurs ou de grappes / fermes (cluster) de calcul. Son utilisation nécessite également des ressources mémoire très importantes et de disposer d'un espace de stockage conséquent.
Partie 2. Compilation du modèle WRF
La compilation se déroule en 2 étapes :
1. la compilation du noyau ARW ;
2. la compilation du système de pré-traitement WRF Preprocessing System (WPS).
Ces deux éléments partagent les routines d’entrées et de sorties WRF I/O API. La compilation se fait sur les machines du cluster du Centre de Calcul de l’Université de Bourgogne (CCUB).
Les librairies nécessaires à la compilation sont :
– Compilateur FORTRAN 90/95 : ici Intel ;
– Compilateur C : ici gcc;
– Perl ;
– NetCDF ;
– MPI ;
2.1 La compilation du noyau ARW
Récupération du code source dans votre répertoire de travail et décompression des fichiers archives :
tar -xf WPSV3.6.1.TAR.gz
tar -xf WRFV3.6.1.TAR.gz
Vous disposez maintenant de deux nouveaux dossiers WRFV3 et WPS. Pour procéder à la compilation afin d’obtenir les exécutables du modèle, il faut :
1. définir les options de compilation en fonction du type de machine, du compilateur et des librairies ;
2. définir l’environnement de compilation parallèle ;
3. lancer la compilation.
cd WRFV3
ls -l
Vous trouvez dans le dossier le contenu suivant :
Registry/ Dossier pour les fichiers Registry
arch/ Dossier de collecte des options de compilation
clean script pour nettoyer les fichiers créés et les exécutables
compile script pour la compilation du code
configure script de génération du fichier configure.wrf
chem/ WRF chimie de la NOAA/GSD
dyn_em/ Dossier du noyau ARW
dyn_exp/ Dossier noyau expérimental
dyn_nmm/ Dossier du noyau NMM
external/ Dossier des paquetages externes pour ES, temps et MPI
frame/ Dossier de WRF framework
inc/ Dossier des fichiers d'entête (include)
main/ Dossier des routines du type wrf.F et des exécutables
phys/ Dossier des modules physiques
run/ Dossier pour l'exécution de WRF
share/ Dossier des modules de médiation et d'ES
test/ Dossier de tests
tools/ Dossier outils de développement
La compilation se réalise avec les commandes suivantes ; elle nécessite des patchs permettant d'optimiser le calcul de certaines routines utilisant des filtres basés sur des transformées de Fourie (dans le code, il s'agit des filtres polaires, activés pour les hautes latitudes).
Le fichier configure.wrf peut être obtenu ICI. Il doit être copié dans le répertoire de travail (WRFV3). Dans l'exemple présent, WRF est compilé en parallèle à l'aide du compilateur fortran Intel.
module load openmpi/intel/13.1.3
module load netcdf/4.3.0/intel/13.1.3
module load jasper/1.900.1/intel/13.1.3
module load hdf5/1.8.11/intel/13.1.3
export WRFIO_NCD_LARGE_FILE_SUPPORT=1
export NETCDF=$NETCDFROOT
export NETCDF4=1
export JASPERINC=$JASPERROOT/include/jasper
export JASPERLIB=$JASPERROOT/lib
export HDF5_PATH=$HDF5ROOT
export CURL_PATH=/usr/lib64
export WRF_EM_CORE=1
tar xvf ../WRFV3.5-CCUBPATCH.tar
./configure
19. Linux x86_64 i486 i586 i686, ifort compiler with icc (dmpar)
Compile for nesting? (1=basic, 2=preset moves, 3=vortex following) [default 1]: 1
cp ../configure.wrf-ompi-intel13.1.1-MKL-FULLOPTIM configure.wrf
patch -p1 < ../0001-mkl-fft-for-polar-filters.patch
./compile -j 20 em_real 2>&1 | tee COMPILE.log
Une fois l'opération terminée, on vérifie que les fichiers exécutables notamment wrf.exe et real.exe sont bien générés.
ls -l main/*.exe
On peut ensuite passer à la deuxième étape, la compilation du WRF Preprocessing System (WPS).
2.2 La compilation de WPS
Note : La compilation de WPS doit obligatoirement être réalisée après celle du noyau ARW.
cd ../WPS
module load netcdf/4.3.0/intel/13.1.3
module load intel/13.1.3
module load jasper/1.900.1/intel/13.1.3
module load hdf5/1.8.11/intel/13.1.3
export NETCDF=$NETCDFROOT
export JASPERINC=$JASPERROOT/include/jasper
export JASPERLIB=$JASPERROOT/lib
./configure
17. Linux x86_64, Intel compiler (serial)
Enter selection [1-26] : 13
cp ../configure.wps-seq-intel13.1.1 configure.wps
./compile 2>&1 | tee COMPILE.log
Le fichier configure.wps peut être obtenu ICI. Il doit être copié dans le répertoire de travail (WPS). Dans l'exemple présent, WPS est compilé en mode séquentiel (code non parallélisé).
Si la compilation est réussie vous devez avoir 3 nouveaux exécutables : geogrid.exe, ungrib.exe et metgrid.exe.
– geogrid.exe : définit la taille/localisation des domaines et extrait les données d’entrée statiques ;
– ungrib.exe : extrait les champs météorologiques des fichiers GRIB ;
– ungrib.exe : réalise l’interpolation horizontale des champs météorologiques (issus de ungrib) à la maille de simulation des domaines (définis par geogrid).
Nous pouvons maintenant passer à la phase de définition du domaine et de pre-processing des données.
Partie 3. Préparation des données avec WPS
La préparation des données passe par la configuration du fichier namelist.wps. Ce fichier est la clé de voute pour la préparation des données. C’est dans ce fichier que 1) la période et l’aire géographique sont définies 2) les données d’entrée statiques et dynamiques utilisées sont sélectionnées, 3) l’interpolation des données à la maille de simulation est effectuée et 4) le format des données est fixé.3.1 Définition des domaines simulation
Il existe deux manières de créer des domaines emboîtés :
– manuellement en ajustant les valeurs de la partie &geogrid du fichier namelist.input ;
– interactivement en utilisant l’interface WRF Domain Wizard.
3.1.1 La localisation et taille des domaines
C’est le premier domaine qui fixe la fenêtre géographique de l’aire de simulation par l’intermédiaire des coordonnées géographiques du centre. Les domaines emboîtés ne sont localisés que par rapport au domaine parent (domaine 1 pour le domaine 2, domaine 2 pour le domaine 3 etc.). La Figure 3.1 présente le mode de localisation utilisé par WPS.Figure 3.1: Localisation des domaines emboîtés
Le domaine 1 est centré sur 45N et 4.7E. Les domaines sont par exemple définis dans le namelist.input comme suit :
&geogrid
parent_id = 1,1,
parent_grid_ratio = 1,3,
i_parent_start = 1,31
j_parent_start = 1,17
e_we = 74,112
e_sn = 61,97
geog_data_res = '10m','5m'
dx = 30000,
dy = 30000,
map_proj = 'lambert',
ref_lat = 45.0,
ref_lon = 4.7,
truelat1 = 42.0,
truelat2 = 47.0,
stand_lon = 4.7,
geog_data_path = '/work/crct/shared/geogv35'
Si ces réglages peuvent sembler peu intuitifs, il est possible d'utiliser l'application WRF Domain Wizard, qui permet de définir les domaines de manière interactive avec interface graphique.
3.1.2 WRF Domain Wizard
Lancer l'application :
wrfdw &
Lors du premier lancement il faut renseigner les chemins d'accès et créer le répertoire qui accueillera les paramètres de localisation. Une fois les domaines définis, les paramètres de localisation générés via wrfdw sont à copier dans la namelist.wps.
3.2 Les trois étapes du preprocessing
Les principales étapes du preprocessing sont résumées par la Figure 3.2.Figure 3.2: Les étapes du preprocessing
3.2.1 Geogrid
Interpolation des champs terrestres statiques à la maille de simulation.
Etape 1 : Edition de namelist.wps
Pour geogrid seuls les éléments &share et &geogrid de namelist.wps nécessitent d’être édités.
– la partie &share permet d’indiquer quel noyau est utilisé (ici ARW), le nombre total de domaines, le format de sortie des données (2=NetCDF) ;
– la partie &geogrid fixe le domaine géographique à simuler, le type de projection géographique et les chemins d'accès aux données de surface.
Les données de surface sont issues de l'USGS (United State Geological Survey), du satellite MODIS, ou d'autres bases de données (exemple : CORINE Land Cover sur l'Europe, modèle numérique de terrain de l'IGN pour la France, etc.). Ces bases contiennent les données de sol, de végétation, de relief, d'albédo. Ces données sont fournies pour 4 résolutions spatiales : 10m-arc, 5m-arc, 2m-arc et 30sec-arc.
&share
wrf_core = 'ARW',
max_dom = 2,
start_date = '1989-01-01_00:00:00','1989-01-01_00:00:00'
end_date = '1992-12-31_18:00:00','1992-12-31_18:00:00'
interval_seconds = 21600,
io_form_geogrid = 2,
/
&geogrid
parent_id = 1,1,
parent_grid_ratio = 1,4,
i_parent_start = 1,29,
j_parent_start = 1,12,
e_we = 80,93,
e_sn = 34,49,
geog_data_res = '10m','2m',
dx = 1.181168,
dy = 1.125966,
map_proj = 'lat-lon',
ref_lat = 45.56,
ref_lon = 4.693,
truelat1 = 45.56,
truelat2 = 45.56,
stand_lon = 4.693,
geog_data_path = '/work/crct/shared/geog'
opt_geogrid_tbl_path = 'geogrid/'
/
Etape 2 : Vérifier que GEOGRID.TBL est lié à la bonne version de table
Il y a plusieurs GEOGRID.TBL en fonction des noyaux dynamiques :
– GEOGRID.TBL.ARW pour ARW ;
– GEOGRID.TBL.NMM pour NMM.
ls -l geogrid/GEOGRID.TBL
GEOGRID.TBL -> GEOGRID.TBL.ARW
Etape 3 : Lancer geogrid.exe
./geogrid.exe
Parsed 11 entries in GEOGRID.TBL
Processing domain 1 of 3
Processing XLAT and XLONG
Processing MAPFAC
Processing F and E
Processing ROTANG
Processing LANDUSEF
Calculating landmask from LANDUSEF ( WATER = 16 )
Processing HGT_M
Processing HGT_U
Processing HGT_V
Processing SOILTEMP
Processing SOILCTOP
Processing SOILCBOT
Processing ALBEDO12M
Processing GREENFRAC
Processing SNOALB
Processing SLOPECAT
Processing SLOPECAT
Processing domain 2 of 3
Processing XLAT and XLONG
Processing MAPFAC
Processing F and E
......
!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
! Successful completion of geogrid. !
!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
Si une erreur survient lors de l’exécution il faut analyser les messages contenus dans le fichier geogrid.log.
Si l’exécution s’est bien déroulée vous devez avoir dans votre répertoire autant de fichiers avec le préfixe geo_em.d0<numéro de domaine>.nc que de domaine.
ls -l geo_em*
geo_em.d01.nc
geo_em.d02.nc
geo_em.d03.nc
3.2.2 Ungrib
Etape 1 : Edition des parties &share et &ungrib de namelist.wps
La partie &share permet d’indiquer la période d’extraction des données et le pas de temps des données (21600=6hrs).
La partie &ungrib indique dans quel format binaire intermédiaire seront les données (WPS, SI, MM5). Le format WPS est recommandé.
Enfin il convient de préciser le répertoire et le préfixe du nom des fichiers intermédiaires qui sont produits.
&share
wrf_core = 'ARW',
max_dom = 2,
start_date = '1989-01-01_00:00:00','1989-01-01_00:00:00'
end_date = '1992-12-31_18:00:00','1992-12-31_18:00:00'
interval_seconds = 21600,
io_form_geogrid = 2,
/
&ungrib
out_format = 'WPS',
prefix = 'FILE',
/
Etape 2 : Faire un lien sur les fichiers GRIB
Les fichiers GRIB sont les fichiers qui contiennent les variables météorologiques, de surface terrestre et des océans de large échelle qui sont utilisées pour fixer les conditions aux bornes.
link_grib.csh /work/crct/shared/ERA_INTERIM/era_int_1990*
ls -l GRIBFILE.*
GRIBFILE.AAA -> /work/crct/shared/ERA_INTERIM/era_int_1990s1_prs.grb
GRIBFILE.AAB -> /work/crct/shared/ERA_INTERIM/era_int_1990s2_prs.grb
GRIBFILE.AAC -> /work/crct/shared/ERA_INTERIM/era_int_1990_sfc.grb
Etape 3 : Utiliser le bon fichier Vtable et exécuter ungrib.exe
Le fichier Vtable est nécessaire à ungrib car il permet d’identifier les variables météorologiques, de surface terrestre et des océans à extraires du fichier GRIB.
Note 1 : Il convient de traiter séparément les données SST des autres données. Ceci nécessite donc de manipuler deux fichiers Vtable : Vtable_prs_anaecm (disponible ICI) et Vtable_sst_anaecm (disponible ICI).
Note 2 : Pensez à modifier le préfixe pour les noms des fichiers intermédiaires. Ici on utilisera 2 préfixes pour les SST d’une part et pour l’ensemble des autres variables d’autre part.
cp Vtable_prs_anaecm Vtable
./ungrib.exe
PRES GEOPT HGT TT UU VV RH DEWPT LANDSEA ...
---------------------------------------------------------
1000.0 X X X X X
_925.0 X X X X X
....
Pensez à éditer namelist.wps pour changer le préfixe des fichiers intermédiaires.
cp Vtable_sst_anaecm Vtable
./ungrib.exe
Inventory for date = 1990-01-08 00:00:00
PRES SST
-----------------------------------------------------------
2001.0 X
-----------------------------------------------------------
....
Si l’exécution se termine par une erreur il faut analyser les messages qui sont contenus dans le fichier ungrib.log.
Si l’exécution est un succès, les fichiers intermédiaires préfixés ont été générés et sont utilisés pour la dernière étape du preprocessing.
3.2.3 Metgrid
Etape 1 : Edition des parties &share et &metgrid de namelist.wps
Ici on s’assurera que tous les préfixes des fichiers intermédiaires sont présents.
&share
wrf_core = 'ARW',
max_dom = 2,
start_date = '1989-01-01_00:00:00','1989-01-01_00:00:00'
end_date = '1992-12-31_18:00:00','1992-12-31_18:00:00'
interval_seconds = 21600,
io_form_geogrid = 2,
/
&metgrid
fg_name = 'FILE' 'SST_FILE'
io_form_metgrid = 2,
opt_metgrid_tbl_path = 'metgrid/',
/
Etape 2 : Vérifier que METGRIB.TBL est lié à la bonne version
Le fichier METGRIB.TBL précise le type d’interpolation en fonction du champ. Il y a plusieurs METGRID.TBL en fonction des noyaux dynamiques :
– METGRID.TBL.ARW pour ARW ;
– METGRID.TBL.NMM pour NMM ;
ls -l metgrid/METGRID.TBL
METGRID.TBL -> METGRID.TBL.ARW
Etape 3 : Lancer metgrid.exe
./metgrid.exe
Si le calcul se termine par une erreur il faut analyser les messages contenus dans le fichier metgrid.log
Si le calcul s’est bien déroulée, les fichiers préfixés met_em ont été créés pour chaque pas de temps et pour tous les domaines. L’étape de préparation des données est terminée. Les fichiers met_em vont maintenant servir pour l’étape de création des “inputs” nécessaires pour l’initialisation et la simulation.
Pour gagner de l'espace disque il est possible (mais bien sûr pas obligatoire), à ce stade, de supprimer les fichiers temporaires générés par WPS :
rm FILE* SST_FILE*
Il peut être pertinent de les conserver pour économiser l'étape ungrib.exe dans l'hypothèse où ces fichiers pourraient être rapidement réutilisés (en ce cas les migrer sous le serveur d'archivage /archive peut être envisageable pour ne pas encombrer inutilement le serveur de travail haute perfoemance /work).
Partie 4. Initialisation et simulation
Les étapes clés de la simulation sont précédées par l’initialisation à partir des fichiers met_em. Ces deux étapes passent également par la configuration du fichier namelist.input. Ce fichier est le noeud du système. Il permet de préciser le pas de temps entre chaque calcul, les schémas physiques retenus, les options de la résolution des équations, le format de sortie, le guidage, etc.
4.1 Le fichier de paramétrisation namelist.input
Voir Wang et al. (2009) pour une description détaillée du fichier, ou le fichier README.namelist qui se trouve dans le répertoire WRFV3/run. Les principaux items du fichiers sont :
– time_control qui fixe la période, le pas des inputs et des fichiers de reprises, le format numérique des simulations ;
– domains similaire à ce qui est contenu dans namelist.wps, fixe le pas de temps pour la résolution ;
– physics permet de paramétrer les 7 principaux processus physiques implémentés :
1. microphysique des nuages mp_physics
2. radiation grande longueur d’onde ra_lw_physics
3. radiation courte longueur d’onde ra_sw_physics
4. schéma de flux de surface (coefficients de friction et d’échange) sf_sfclay_physics
5. schéma d’interaction de surface (Land Surface Model) sf_surface_physics
6. couche limite planétaire bl_pbl_physics
7. physique des cumulus cu_physics
– fdda permet de guider le modèle ("nudging" spectral ou en points de grille);
– dynamics options de diffusion, d’advection ;
– bdy_control contrôle la prescription des conditions aux limites atmosphériques.
Potentiellement l’ensemble des options physiques de base offrent plus de 600 000 combinaisons différentes. Le choix des options est une étape délicate de la simulation numérique climatique. Il n’existe pas de combinaison universelle.
4.2 Création des fichiers d’initialisation avec real.exe
Les fichiers d’initialisation et de rappel du modèle sont constitués à partir des fichiers met_em et des items time_control, domain du fichier namelist.input et de l’exécutable real.exe.
Note 1 : real.exe et wrf.exe doivent être éxécutés en mode batch. Pour cela on utilisera les scripts batch realjob (exemple ICI) et wrfjob (exemple ICI), placés dans le répertoire WRFV3/run.
Note 2 : il faut éditer ces scripts batch pour jouer sur le nombre de processeurs utilisés pour le calcul. C’est le système de gestion de batch SGE (Sun Grid Engine) qui se charge ensuite de la répartition en fonction de la charge du cluster.
Note 3 : il existe une option permettant d'archiver des sorties additionnelles à des pas de temps plus fins (par exemple, températures ou pluies horaires). Les détails de la syntaxe sont indiqués dans le README.namelist mais cette option requierts des fichiers texte, à placer dans le répertoire WRFV3/run, listant les paramètres à archiver et la fréquence souhaitée d'archivage. Il en faut un par domaine de simulation : l'exemple fourni ICI permet de sauvegarder les pluies convectives (RAINC), non convectives (RAINNC), la température à 2 mètres (T2) et le vent à 10 mètres (U10, V10).
cd WRFV3/run
ln -s ../../WPS/<votre répertoire met file>/met_em* .
module load openmpi/intel/13.1.3
module load netcdf/4.3.0/intel/13.1.3
module load intel/13.1.3
module load jasper/1.900.1/intel/13.1.3
module load hdf5/1.8.11/intel/13.1.3
qsub realjob
Un fois le process terminé vous devez avoir dans votre répertoire le fichier wrfbdy_d01 et autant de fichiers que de domaines wrfinput_d0<numéro du domaine>. Si les options de guidage sont activées (grid_fdda = 1 ou 2 dans la section &fdda de namelist.input), des fichiers wrffdda_d0<numéro du domaine> sont également créés. A ce stade la simulation climatique peut être lancée.
4.3 Simulation avec wrf.exe
Editer wrfjob pour choisir le nombre de processeurs sur lequel s’exécutera le calcul. Il ne reste ensuite qu’à soumettre le job et attendre.
rm rsl.*
module load openmpi/intel/13.1.3
module load netcdf/4.3.0/intel/13.1.3
module load intel/13.1.3
module load jasper/1.900.1/intel/13.1.3
module load hdf5/1.8.10-patch1/intel/13.1.3
qsub wrfjob
Les résultats sont contenus dans les fichiers wrfout_d<numéro du domaine>_<date de départ> au format NetCDF (.nc). Une fois ces fichiers créés et le job terminé, les fichiers temporaires peuvent être détruits.
rm met_em* wrfrst* wrfbdy* wrfinput* rsl.* *.o* *.po*
Choix du nombre de processeurs
En pratique le cluster de l'université de Bourgogne autorise des jobs à tourner sur un maximum de 64 processeurs. Toutefois, le code lui-même peut parfois apporter des restrictions supplémentaires. La formule empirique ci-dessous permet de calculer le nombre maximal de processeurs à ne pas dépasser, en fonction de la taille du domaine simulé (nombre de points de grille en latitude et longitude) :
– soient M et N le nombre de points de grille en latitude et longitude, respectivement
– pour le premier domaine WRF, on calcule E(M/6) et E(N/6) où E est la fonction mathématique partie entière
– NPROC = E(M/6) * E(N/6)
– si l'expérience utilise des domaines emboîtés (nesting, cf. partie 1.1.2), les mêmes opérations sont répétées pour les domaines nestés, en remplaçant le facteur 6 par 9.
– le nombre de processeurs maximal à retenir correspond à la plus petite des valeurs ainsi trouvées, pour les k domaines simulés.
Note 1 : l'architecture des machines de calcul suggère de choisir un nombre de processeurs qui soit un multiple de 8.
Note 2 : le temps d'attente des jobs est d'autant plus long que le nombre de processeurs est élevé, il s'agit donc de trouver un bon compromis entre temps d'attente et temps d'exécution en fonction de la charge du cluster.
Note 3 : les gains en temps d'exécution ne sont pas linéaires en fonction du nombre de processeurs.
Bibliographie
W. C. Skamarock, J. B. Klemp, J. Dudhia, D. O. Gill, D. M. Barker, M. G. Duda, X.-Y. Huang, W. Wang, and P. J. G. A description of the Advanced Research WRF Version 3. Technical report, National Center for Atmospheric Reasearch, Boulder - Colorado , USA, 2008. 125p.
W. Wang, C. Bruyère, M. Duda, J. Dudhia, D. Gill, H.-C. Lin, J. Michalakes, S. Rizvi, and X. Zhang. ARW Modeling System User's Guide version 3.1. NCAR, Boulder - Colorado, USA, April 2009.